
End-to-end performance in GigaSunet
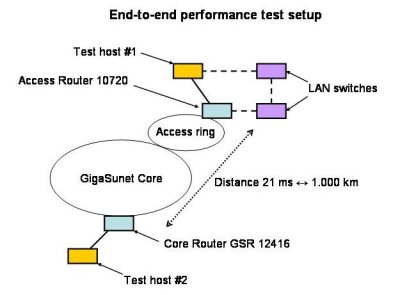
To be able to do this, two test machines are connected - one connected with Gigabit Ethernet to one of the core-routers in Stockholm, and the other one (also with Gigabit Ethernet) to one of the access routers at Luleå university of technology, in the northern part of the country.
Round-trip-time between the sites are approx. 21 ms (distance is approx 1.000 km, 620 miles). These machines are available for testing on the production network, shared with several hundred thousand users across Sweden.
The program ttcp can is usually included as a package in most Unix/Linux systems, otherwise the source code can be downloaded from ftp.arl.mil. There are also a number of Windows versions available, for example pcattcp from pcausa or ntttcp which is included in the Windows 2000 DDK. The same is true for iperf which can be downloaded from NLANR. Note that the original ttcp program has a flaw, that is not affecting the test itself, but the presentation of the result.
If You ask for presentation of data as megabit/sec (as specified by setting the "-f m" flag), the actual test result in bits/sec is divided by 1024*1024, which is wrong - according to the spec, as 1 Mbit/sec is defined as 1.000.000 bits/sec, not 1.048.576. Similar errors occur if You ask for kilobit/sec or gigabit/sec formats.
The tests conducted between the test machines shows that utilizing this bandwidth for a single, long-distance connection is not as easy as many believe. The problem is not in the network itself, but in the end hosts.The TCP parameters at the end hosts are by default set much too low for this type of connections, as speed of light are a limiting factor. Until someone figures out how to increase the speed of light, we have to tune the operating system.
A good description on the underlying factors of high performance data transfers can be found here. Despite that that page is a little bit old, and thus lacks information on the latest operating systems, the background description is very good.
Results
The net result of the tests is that the GigaSunet network is quite capable of handling a full gigabit nationwide connection. During several tests with the following parameters: ttcp -s -t -f m -l 61440 -n 20345 remote.host (parameters set for a test that will last 10 seconds) we got repeatable results of 966,5 Mbit/sec on the test path described above, which is very close to the theoretical maximum, especially for such a short test. Running this test for a longer period of time gives the same result, this shows that the quality of the network is very good - at these speeds there are about 83000 packets/second sent, and if only one packet is lost the transfer speed will be degraded significantly.
As the diagram below shows, the throughput is very dependant on the TCP window size - either You have to use a good auto-tuning mechanism, or You have to tune this yourself.
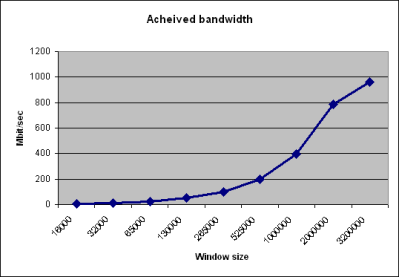
Many operating systems are delivered with TCP window sizes set to 16384 or 32768. As You can see in the table, it is possible to increase the throughput by a factor of 100 just by changing that to a more reasonable value.
World record
As a result of the tests described above we continued our efforts, with almost the same setup, and are as of spring 2004 proud holders of the Internet Land Speed Record! More details on the world record can be found here.
Observations
The central problem with high-speed TCP communication over long distances is that it becomes very fragile to packet losses. This is due to the nature of traditional TCP, and the problem becomes more and more visible the longer the communication path is. A more technical description of why this really happens can be found here.
Communication speed problems are likely to be in the end-points of the network, or close to the end-points. Because of the sensitivity of TCP even network equipment that are quite high quality may kill a TCP connection over long distances. A typical example of this situation is if the end-machine is connected to a switch with almost no other traffic, there may be packets lost due to other "administrative" packets being sent (CDP, OSPF updates, rwho broadcasts, ARP requests etc.) that consumes bandwidth.
Even if as few as 1 out of 10000 packets is lost it may cause a significant degradation of performance. Note that this performance downgrade will not be noticeable if the machines are connected close to each other (like in the same switch) because the round-trip-time will be ignorable.
Another common situation where it is not obvious that packets will be lost is if there is ethernet trunking involved in the communication path somewhere and the resulting bandwidth will significantly be larger than the communication flow bandwidth. For example, if there is a communication path trunked over two 1 Gbit/sec paths, and the other traffic only uses 100 Mbit/sec shared over these two paths, there will still be a significant packet loss. This is because the trunking equipment will do some hashing of each flow and thereafter always sent via one specific of the two paths, to avoid reordering of packets in a communication flow (packet reordering is also bad for TCP flows).
When looking at the traffic stream, it shows that the speed is downgraded already in the startup phase of the communication flow. A reason for this is the (somewhat aggressive) injection of packets into the network which is called "slow start" (exponential, increase the send window one segment per returned ACK).
For a long-distance connection, there will also be a "burst" factor increasing large packet losses in the initial phase. The "burst" factor is caused by long round-trip-times in the network and that new packets are only sent when ACKs are received. This phenomenon is described more extensive on this page.
The transmitter (and receiver) may be unneccessary loaded due to small receive buffers in the application on the receiving machine. This also generates an unexpected amount of network traffic in the return direction to the transmitting machine.
There are two types of information that is sent back to the transmitter that generates return traffic; one is pure ACKs for received segments and the other is receive window updates. By convention ACKs are sent at least one for two received segments, and window updates each time the application reads in data. More information about receive traffic problems are described in this web page.
Further work
More investigations in this area will be performed and thereafter more information added to this web page.